 Андрей Мамон
Андрей МамонМетодика чистки семантического ядра в Кей Коллекторе
В ходе парсинга через Кей Коллектор неизбежно приезжает большое количество мусорных запросов, которые либо не подходят к нашей тематике, либо содержат различные спец. Символы, частотность которых в итоге окажется равной 0. Кей Коллектор обладает очень универсальным и гибким функционалом для чистки поисковых запросов и может справиться с любым их количеством достаточно быстро. Рассмотрим большинство из них и разберемся как ими управлять.
Чистка с помощью фильтров
В Кей Коллекторе присутствует возможность так называемой “быстрой фильтрации” и более широкой фильтрации, которая подойдет абсолютно любому пользователю КК.
Быстрый фильтр позволяет нам отфильтровать слова, которые содержат заданные параметры. Сам фильтр находится над рабочей областью поисковых фраз.

Рассмотрим на примере: допустим, у нас коммерческий сайт по продаже различной техники и мы собираем семантику для страницы кондиционеров. Собрав поисковые запросы с помощью КК обнаружили, что часть из них содержит слова “бесплатно”, “бесплатный” и другие словоформы этого запроса. Чтобы быстро отсеять ненужные нам запросы можно использовать быстрый фильтр, для этого необходимо вбить в строку “бесплат” и нажать Enter.

Необходимо использовать именно вариант “бесплат” для того, чтобы охватить все словоформы и чтобы нам не пришлось искать каждое склонение вручную.
После этого система выдаст нам все запросы из группы, которые содержат именно эту последовательность букв в любой части фразы.
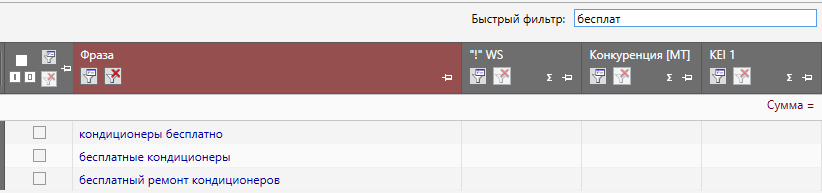
Остается лишь выделить все фразы.

И перенести их в папку “МУСОР”, согласно нашей методике сбора, в которой фразы не удаляются, а остаются для упрощения следующих итераций.
С этим инструментом желательно быть аккуратными, так как он имеет свои недостатки и просто фильтрует по набору и очередности букв (учитывая пробелы). Допустим, если мы работаем с коммерцией и хотим найти какую-либо компанию с названием-аббревиатурой ЕСК, то при использовании быстрого фильтра КК выдаст нам все слова, содержащие этот набор букв, а их будет немало. В тоже время он поддерживает регулярные выражения. Если вы столкнулись с ситуацией, когда быстрый фильтр уже не подходит - переходим к более широкой фильтрации.
Чтобы фильтровать фразы в многоуровневом режиме жмем на данную кнопку.

Перечень возможных фильтров достаточно широк
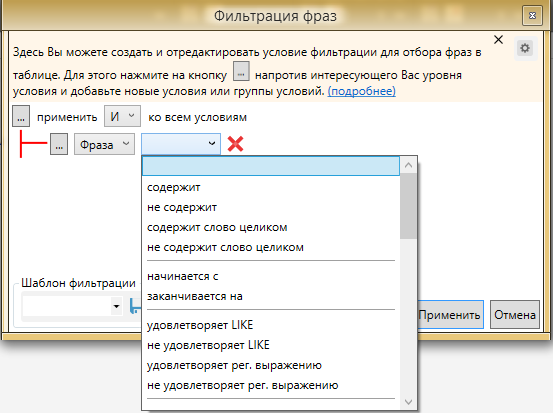
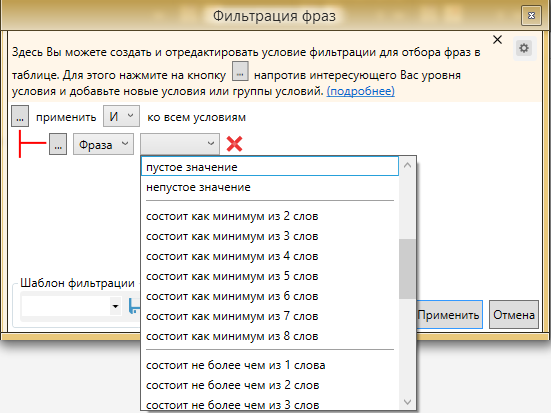
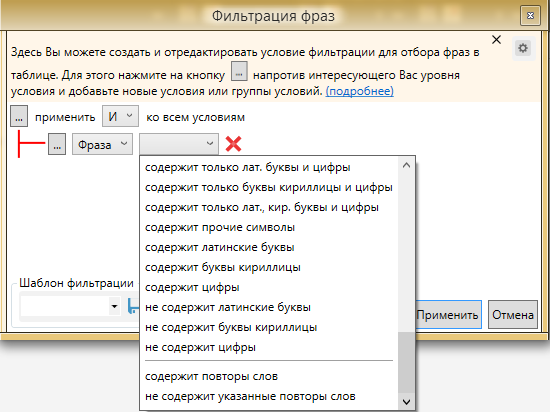
Уже этого набора фильтров будет достаточно даже самому привередливому пользователю.
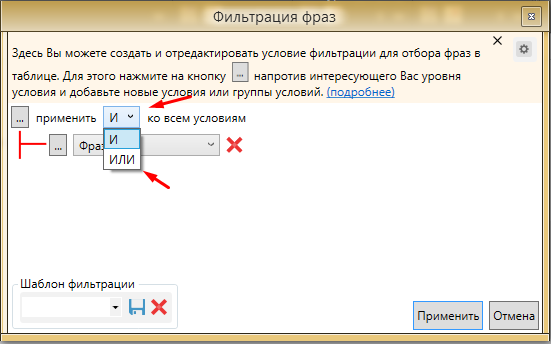
Увеличивает возможности этого фильтра многоуровневая фильтрация, то есть возможность задать несколько фильтров одновременно. Для этого необходимо нажать на кнопку “...” и добавить “Условие внутрь”. Так же можно сразу добавить несколько групп фильтраций (“Добавить группу внутрь”) и настроить уже в них свои правила.

Таким образом мы можем отфильтровать фразы по всем параметрам сразу. При переключении опции “И” на “ИЛИ” система будет рассматривать несколько вариантов фильтрации, а не связывать их. Это позволит задать сразу все фильтры в один проход.
Для сброса фильтрации используем эту кнопку

Рассмотрим наиболее часто применяемые фильтры.
Прочие символы

Этот фильтр поможет нам отсеять все фразы, содержащие специальные символы, которые по какой-то причине не отфильтровали на этапе сбора. Под прочими символами КК понимает следующие: \ / ? ( ) ; , ” и другие более специфические (остальные удаляются через настройки, если добавлены в них). Как показывает практика, подобные запросы часто имеют низкую, а в некоторых случаях и нулевую частоту. Если нам надо, чтобы фразы которые содержат , или ? оставались в списке, но не отображались символы - это можно изменить в настройках КК выставив опцию для автоматической замены или удаления этих знаков.
Латинские буквы

Этот фильтр будет полезен в большей степени для информационных сайтов, не связанных с названием каких-либо продуктов или товаров. Для коммерческих сайтов очень часто используются официальные названия на латинице и данный фильтр может существенно порезать семантическое ядро проекта.
Важно! Рекомендуем его использовать только в проектах, в которых латиница не встречается в “рабочих” фразах. Именно в этом случае этот фильтр оказывается очень удобным и быстрым в использовании.
Запросы с одной буквой в конце
Нередко в ходе парсинга через КК нам приезжают запросы по типу “как сделать прическу из”, “ловля рыбы в”, “купить компьютер за” и подобные выражения, которые либо являются неоконченными, либо имеют повторяющиеся слова. Про повторы поговорим чуть позже, в этом случае фильтр подойдет больше для одиночных букв в конце.
Делаем следующие настройки:
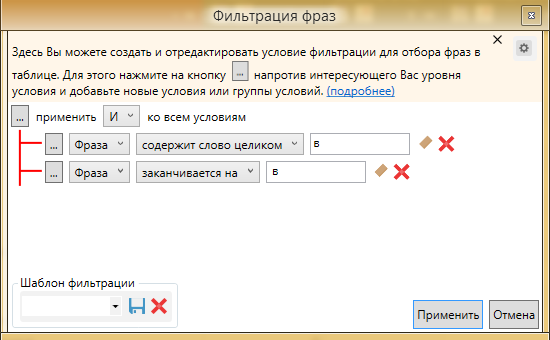
Условие оставляем “И”, так как эти параметры должны быть связаны. Фраза “заканчивается на”, перед нужной буквой обязательно ставим пробел. Иначе нам приедут запросы по типу “в Ростов”.
Данный способ очень удобен. Можно сохранить этот шаблон и применять его во всех проектах. Для сохранения шаблона проводим следующую операцию.
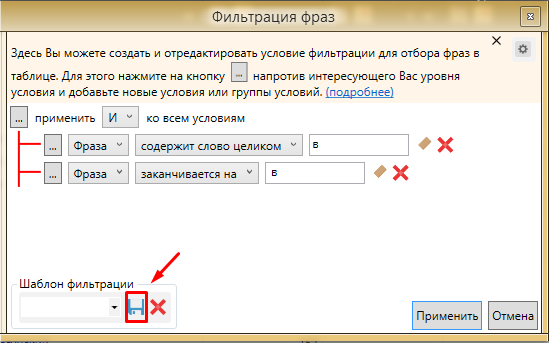

Вводим название и сохраняем шаблон. Теперь во всех проектах можно использовать этот фильтр, остается только менять букву в конце.
Если менять букву не хочется и хочется всё разом, можно добавить более объемный и жесткий вариант. Будет выглядеть он примерно так:
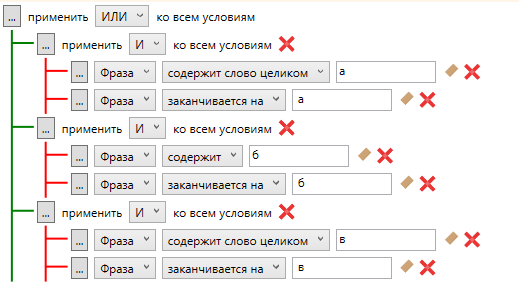
Этот способ из разряда - все и сразу и подойдет для тех, кто работает с большими ядрами в поточном режиме. Либо для тех, кто ненароком добавил подсказки Mail.ru как источник парсинга. Можно подобным методом пройтись по всему алфавиту и сохранить это в шаблон. Один раз помучившись мы сможем применять его в любом проекте и разом вычищать большой пласт мусора.
Обратите внимание! Вместо одиночной буквы можно поставить любой предлог или слово, которое подходит под ваш случай.
Чистка на повторы слов
Еще одной проблемой при парсинге являются фразы с повторяющимися словами, например такие как “как почистить картошку как”, “чистим историю браузера историю” и другие нелепые фразы, которые приезжают в основном из подсказок. В некоторых случаях они могут доходить до 10% запросов итерации. Чтобы почистить ядро от подобного мусора нам помогут опять же фильтры в связке с еще одним инструментом Кей Коллектора.
Не рекомендуем использовать только фильтрацию “содержит повторы слов”, так как в этом случае мы получим запросы, которые могут содержать повторы предлогов, что не всегда коверкает ключевую фразу. Лучше использовать связку “содержит повторы слов” и маску запросов QUERY. QUERY - метрика вордстата, которая, грубо говоря, определяет последовательность слов в запросе пользователя и отображает информацию, какой из вариантов наиболее часто используется пользователем. К сожалению, точная частота !WS не может похвастаться этим и показывает нормальную частоту несмотря на повторы слов.
Итак, для начала нам необходимо собрать QUERY для наших запросов, эта информация потребуется нам также для чистки дублей.

После того, как собрали данные, задаем следующий фильтр:
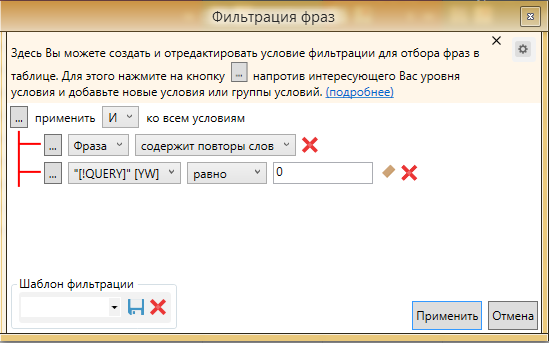
Подобный способ поможет отсечь самых ярких представителей повторов, которые довольно сложно найти другими способами. Чтобы очистить более широко, так как не всегда QUERY может равняться 0, порой это значение может быть в рамках 1-15, в зависимости от точной частоты фразы !WS. Но, чтобы не фильтровать фразы с точной частотой в пределах 5-15, также потребуется добавление параметра. Выглядеть это будет следующим образом.
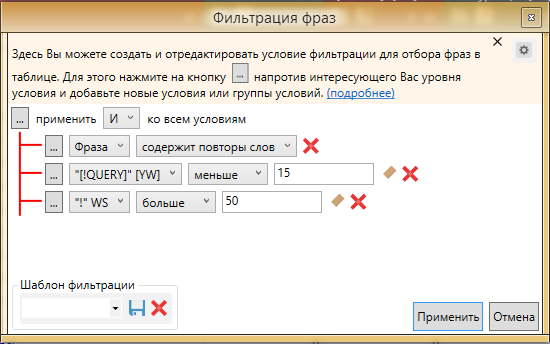
В этом случае мы выделим большинство фраз, в которых есть повторы и при этом не зацепим фразы с повторяющимися предлогами. Добавлять частоту !WS лучше после чистки со значением QUERY = 0. Вы можете настроить оптимальные параметры связки QUERY + WS после пары экспериментов и тестов в своем проекте.
Как видно из всех возможных применений - широкая фильтрация невероятно гибкий инструмент в Кей Коллекторе, который позволяет выстраивать многоуровневую фильтрацию. Еще один плюс - это возможность сохранения всех шаблонов в настройке программы независимо от проекта. Таким образом, один раз создав все необходимые шаблоны, мы можем очистить любое собранное ядро.
Стоп слова
Следующий популярный и достаточно удобный способ чистки фраз в КК - стоп слова.
Стоп слова в данном случае список фраз и слов, которые не подходят нам и мы хотим их вычистить из нашего проекта. По сравнению с фильтрами имеет свои достоинства и ограничения.
Чтобы перейти в раздел стоп слов необходимо нажать на иконку во вкладке “Сбор данных”

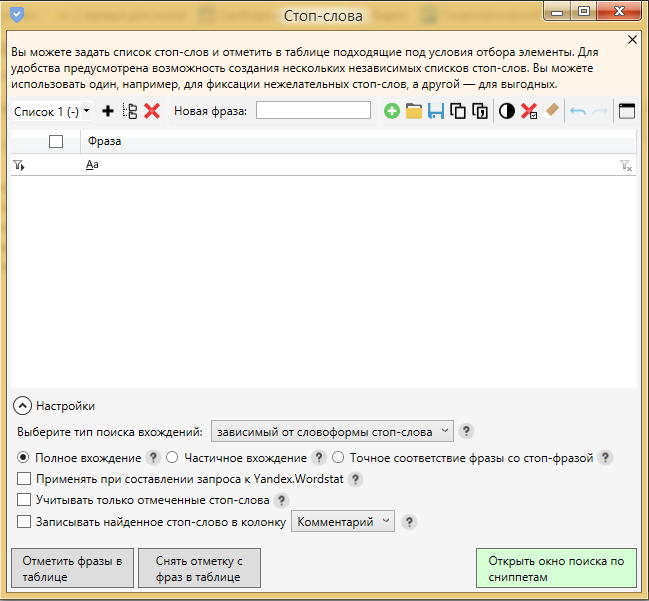
Для добавления стоп слов мы можем использовать импорт из готового файла или вписать фразы вручную.
Допустим, у нас коммерческий проект и нас не интересуют информационные направления запросов. В этом случае мы можем добавить слова по типу “бесплатно”, “своими руками”, “в домашних условиях” и прочие в список стоп слов.

После добавления нужных нам слов жмем “Отметить фразы в таблице”

Система отметит нам нужные слова и мы можем перенести их в папку “МУСОР”. Минусом именно этой стандартной настройки является то, что фразы не изменяются по словоформе и вариант “бесплатный” уже не будет найден. Чтобы избежать этого необходимо изменить настройку “зависимый от словоформы стоп-слова” на независимый и добавить полную форму слова, а именно “бесплатный”.
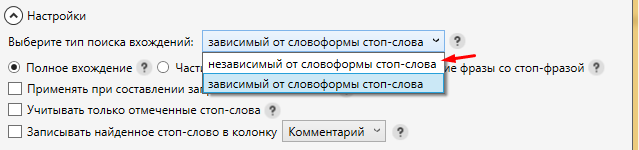
Включение данной опции позволяет КК самому определять и менять словоформу стоп-слов. В большинстве случаев данный способ помогает найти всевозможные варианты. Однако есть одно большое НО! Кей Коллектор “слишком хорошо” меняет словоформы и бывают случаи, когда при добавлении одного слова в итоге могут быть отмечены слова с похожим корнем или набором букв. Например: при добавлении города Зеленоград в список стоп слов, независимая от словоформы фильтрация выделит слова “зеленый” и его производные. Выходом из ситуации может послужить создание двух разных списков минус слов: один, который подходит под изменение словоформы, второй, который требует только зависимой от словоформы отметки.
Важно! Если используете не проверенный и подготовленный список стоп-слов - проверяйте какие слова захватывает инструмент “Стоп-слова” при включенной опции “независимый от словоформы”. Вы можете потерять важные фразы, если система неправильно определит словоформу!
В любом случае, стоп-слова являются оперативным способом чистки, если у нас наготове есть необходимые списки минус слов.
Еще одним удобным способом добавления стоп-слов в список является кнопка в рабочей области фраз

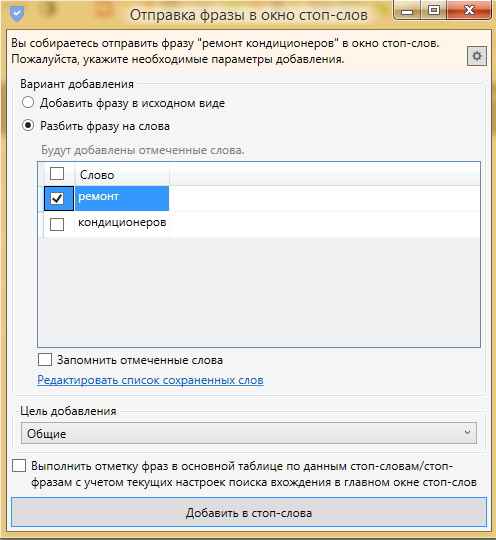
Таким образом мы можем добавить слово в стоп слова и сразу же выделить все фразы, которые включают это слово.
Анализ групп
Анализ групп довольно удобный инструмент для работы с семантическим ядром и для его чистки. Для доступа к этому инструменту необходимо перейти на вкладку “Данные”.

Сам из себя инструмент представляет разбивку всех фраз проекта на слова и совмещенный по группам и словоформам.
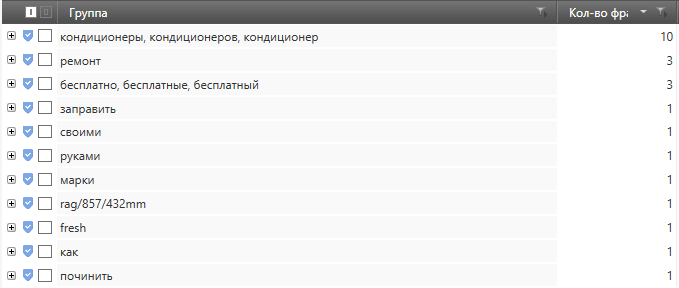
При раскрытии группы мы можем посмотреть все фразы, которые в ней содержаться и убрать отметку с тех, которые могут нам пригодиться.

С помощью инструмента мы можем выделить сразу весь блок фраз и словоформ в нем. Способ достаточно быстрый и эффективный. Разве что следует обращать внимание на словоформы в списке, так как порой туда попадают совсем не те слова и с них приходится снимать отметку вручную. После выделения нужных слов переходим в основное окно и переносим фразы в “МУСОР”. Чтобы удалить перенесенные фразы из анализа групп выполняем перерасчет группы.

Здесь же можно использовать быстрый фильтр по фразам, чтобы найти нужную группу.
Данный метод больше подойдет для работы с маленькими ядрами, так как в больших нередки случаи, что список из анализа групп может быть очень большим и при этом разбит по 1 фразе. Либо же для быстрой отметки 100% ненужных направлений, которые мы знаем и можем вбить в быстрый фильтр.
Анализ неявных дублей
Анализ дублей - это один из способов чистки семантического ядра в Кей Коллекторе. Заключается он в том, чтобы отсечь поисковые запросы, которые отличаются только очередностью слов в них и оставить наиболее часто встречающиеся формулировки.
Например, этот инструмент подскажет, какую фразу оставить “как купить квартиру” или “купить квартиру как” и более сложные варианты в автоматическом режиме.
Анализ дублей лучше всего проводить в конце всех итераций сбора перед непосредственным запуском ядра в работу.
Для того, чтобы использовать инструмент необходимо собрать такой показатель как QUERY.
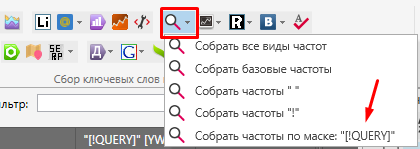
Он наиболее хорошо подходит для данной задачи и определяет частоту определенной маски запроса пользователя. Хотя в самом Кей Коллекторе рекомендуется использование частоты Google Adwords.
Чтобы запустить анализ неявных дублей перейдем на вкладку “Данные”

Устанавливаем следующие настройки

В этом инструменте такая опция как “не учитывать словоформы” работает в другом режиме за счет использования QUERY как критерия отбора. По факту мы можем отключить эту опцию и тогда у нас останутся запросы “какая стиральная машина лучше” и “какие стиральные машины лучше”. Семантического смысла это не меняет, а поисковые системы сами неплохо учитывают словоформы, поэтому нагружать ядро практически одинаковыми фразами с разной частотой нет смысла, достаточно оставить самую частотную из них.
После этого запускаем “Умную отметку”. Инструмент выделит нам фразы, которые сразу можно оценить в этом же окне. В целом, очень редко бывают случаи, когда умная отметка работает плохо либо пропускает какие-то дубли. Переносим получившиеся фразы в папку “ДУБЛИ”. О подготовке папок речь шла в статье о методике сбора в КК.
Анализ дублей позволяет вычистить тот пласт “мусора”, с которым не справятся другие фильтры и инструменты, поэтому стоит всегда использовать его в ходе чистки СЯ.
Чистка фраз по частоте
Еще одним способом чистки поисковых запросов можно назвать фильтр фраз по точной частотности. После сбора частоты !WS необходимо отсеять малочастотные направления. В нашей методике используются запросы с частотой 5 и выше. Эта цифра может быть другой в вашем случае. Стоит отметить, что этот показатель взят не для контекстной рекламы.
Для чистки по частоте подойдут уже рассмотренные фильтры. Для быстрой настройки используем фильтрацию сразу на !WS, а не на фразе.

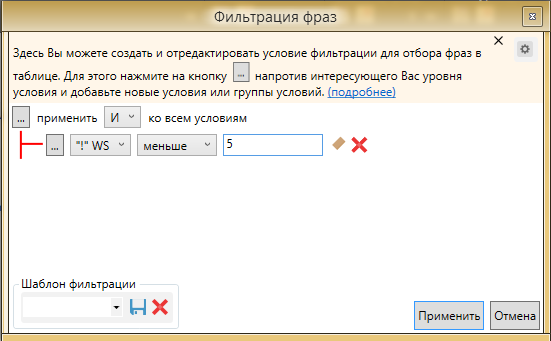
Этот фильтр используется практически всеми и везде, единственное что подлежит изменению - точная частота, которая необходима под каждый проект.
Итоги
Мы постарались рассмотреть наиболее часто встречающиеся методы чистки семантического ядра в Кей Коллекторе. Все эти методы используем мы сами и проверили на множестве проектов. Порядок чистки вы можете выбрать сами, однако наиболее эффективный и быстрый вариант выглядит таким образом:
- Прочие символы.
- Латинские буквы (если позволяет проект).
- Одиночная буква в конце.
- Чистка через стоп-слова.
- Анализ групп.
- Чистка по частоте (можно и раньше, если ядро большое и не жалко денег на антикапчу).
- Повторы слов по QUERY + фильтр “повторы слов”.
- Анализ неявных дублей.
Пройдя по своему семантическому ядру подобным образом в каждой итерации мы сможем получить качественный набор поисковых запросов (при условии, что вручную вычистили ненужные направления через анализ групп).
