 Андрей Мамон
Андрей МамонСбор данных в Кей Коллекторе от А до Я
Парсинг ключевых слов для семантического ядра через Кей Коллектор на текущий день является одним из лучших решений в этой области. Программа представляет собой мощнейший инструмент для работы с СЯ и ключевыми фразами, начиная от их сбора, заканчивая группировкой. Сбор данных играет ключевую роль, так как именно от него зависит насколько полное семантическое ядро мы соберем. После настройки КК приступим к подготовке программы для сбора данных. Вся подготовка и настройка в данной статье производится без привязки к региону.
Выбор источников
Источников для сбора семантики существует немало и Кей Коллектор может похвастаться работой с большинством из них. Собирая ключевые фразы из разных баз и ресурсов мы имеем возможность получить максимально полное семантическое ядро. Однако в то же время есть возможность насобирать столько всего, что на одну чистку и обработку уйдет не один день. В идеале требуется соблюдать некий баланс между полнотой ядра и скоростью работы с ним. Основываясь на практике работы с разными ядрами, оптимальный список источников будет выглядеть так:
Пакетный сбор фраз из левой колонки Yandex.Wordstat.

Когда речь идет о сборе ключевых слов, первым в большинстве случаев вспоминается Яндекс.Вордстат. Добавление данного источника позволит нам спарсить левую колонку сервиса по маркерным словам, то есть не только само слово, но и все, что с ним упоминается.
Плюсы источника:
Большое количество реальных запросов от пользователей, которые пользуются поисковой системой.
Актуальные запросы, обновление раз в месяц.
Возможность на этапе отбора маркерных слов оценить объем семантики по фразе.
Минусы источника:
Парсинг проходит до 40-й страницы, для более глубокого парсинга необходимо несколько итераций.
2. Пакетный сбор слов из Rambler.Adstat.

Этот источник скорее является дополнением к первому. Поисковая система Rambler не пользуется большой популярностью, но, как показывает практика и из нее есть возможность получить ряд интересных фраз для добавления в СЯ.
Плюсы источника:
Дополнение к фразам, собранным из Вордстата.
Независимая и уникальная база слов поисковой системы.
Минусы источника:
Небольшое количество слов в базе.
Большинство фраз не будет добавлено, так как они уже “приедут” из Вордстата.
3. Пакетный сбор поисковых подсказок.

Этот инструмент позволяет получать поисковые подсказки из ряда поисковых систем и ресурсов. То есть мы можем получить “предложения” поисковой системы к фразе, которые вбивает пользователь, основываясь на прошлых запросах и их частоте. Подсказки очень актуальны, так как их обновление происходит чаще, чем баз. Это обусловлено желанием предлагать пользователю только свежую и популярную информацию. Например, ПС Яндекс обновляет подсказки примерно раз в день.

Хороший результат показывают отмеченные на картинке источники подсказок: Yandex, Google (SAFE), YouTube (SAFE), Yandex.Direct (SAFE). В источниках Google, YouTube и Yandex.Direct необходимо установить режим SAFE (безопасный), так как в противном случае будут использоваться перебор подсказок, что может привести к санкциям от этих ресурсов.
Важно! Не советуем использовать подсказки Mail.ru в работе с большими ядрами. Система, использующая сбор подсказок работает по принципу перебора букв алфавита к каждой предложенной фразе. В Mail.ru, если подсказок не найдено, то парсится запрошенная системой буква, то есть сбор подсказок по фразе “окна” будет иметь вид “окна а”, “окна б” и так далее. На 1 000 фраз мы получим как минимум 5 000 таких мусорных запросов. Это потратит время и на парсинг и на их чистку.
Плюсы источника:
Актуальная информация, частое обновление.
Поисковая система сама подбирает нам самые популярные поисковые запросы.
Минусы источника:
Система работает по принципу перебора букв, в некоторых случаях по принципу перебора популярных окончаний к фразе. В итоге мы получаем неестественные фразы с одинаковыми окончаниями. В Яндексе часто попадается окончание “5 лучших моделей”. Да, можно найти рабочую фразу, но когда данная подсказка добавляется к “как вылечить простуду 5 лучших моделей”, то это не более, чем мусор. Еще одним вариантом является “отзывы сотрудников” и “N букв”, где N - цифра от 1 до 10 (решение кроссвордов). В больших проектах данные словосочетания можно заранее включить в список стоп-слов, так как их будет много, а ценности они практически не несут, разве что это наша тематика и найдется рабочая фраза.
4. Сбор расширений ключевых фраз.
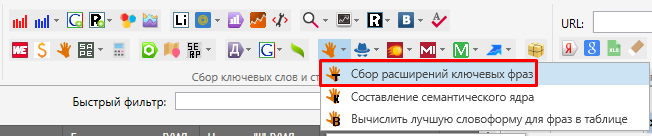
Расширения ключевых фраз предлагают работу со статистикой сервисов Rookee. Инструмент на выходе дает неплохое количество фраз, которые не всегда есть возможность зацепить при парсинге из предыдущих источников.
Плюсы источника:
Уникальные фразы, которые не получить из парсинга ПС.
Довольно чистый итоговый результат, без мусора, так как сервис Rookee имеет хорошие базы и статистики.
Минусы источника:
Не найдено.
5. Следующий источник, который используется для создания полного семантического ядра не входит в инструменты КК. Речь идет о базах ключевых слов. Хорошим вариантом будет бесплатная база Букварикс (www.bukvarix.com). В базе находится более 2 млрд слов и фраз, которые можно добавить в свое семантическое ядро.
Обратите внимание! Убедитесь, что у вас хватает памяти на жестком диске для скачивания базы, так как она занимает 170 гигабайт.
Плюсы инструмента:
Очень большое количество ключевых фраз.
Отдельным плюсом базы в целом является наличие больших списков минус-слов, которые можно позаимствовать для чистки СЯ.
Минусы инструмента:
Часто бывает, что многие фразы баз неактуальны, так как хранятся там долгое время, а обновление таких объемов может проводиться порой раз в 6 месяцев.
Большое количество фраз является и минусом баз, так как собраны все тематики и есть возможность зацепить много мусора при сборе. Поэтому всегда добавляйте стоп-слова как в самой базе, так и после добавления в КК, потому что система изменения словоформы базы работает хуже, чем та же система в КК.
Это основные источники, которые показывают хороший результат и позволяют сохранить баланс качество / скорость в сборе семантического ядра.
Подготовка папок
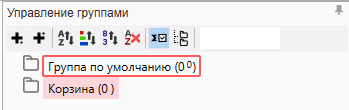
С источниками познакомились, теперь необходимо настроить рабочую область папок, с которыми мы будем работать на этапе сбора данных. Стандартный вариант при создании нового проекта в КК выглядит так:
В соответствии с нашей методикой сбора, которая будет описана далее, необходимо подготовить проект следующим образом.
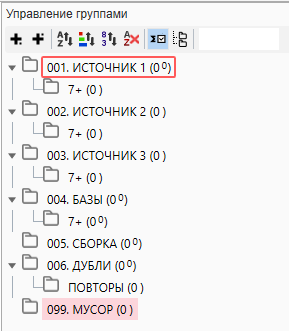
Немного комментариев к этому непонятному “дереву”. Для простоты использования мы пронумеровали папки по типу “001, 002” и так далее и отсортировали их в алфавитном и числовом порядке.
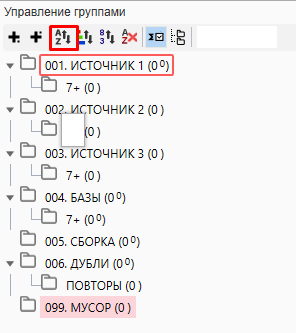
Такой запас чисел необходим в том случае, если группировка будет проходить в Кей Коллекторе, а в работе с большими ядрами количество папок может доходить до сотни.
Создание подпапки 7+ в каждом источнике необходимо для того, чтобы перенести полученные фразы которые состоят из более чем 7 слов. Дело в том, что при сборе частоты, сбор через Яндекс.Директ не может работать с фразами, которые состоят из более чем 7 слов и для получения точной частоты по ним необходимо проводить сбор через Вордстат. Чтобы ускорить процесс и проводить сбор параллельно, лучшим способом будет разделить все фразы на “до 8 слов” и “8 и более”. Это позволит Директу не “спотыкаться” при сборе об такие фразы, а Вордстату не обрабатывать то, что в разы быстрее сделает Директ.
Папка “ДУБЛИ” потребуется для чистки фраз по типу “купить квартиру”, “квартиру купить”. Те фразы, которые меньше употребляются пользователями отправятся сюда.
Итерации сбора
Итак, рабочая область готова, источники выбраны, теперь можно приступить к самому главному - сбору данных.
Сразу стоит отметить, что мы будем описывать сбор максимально полного семантического ядра, ведь именно такое ядро даст понять намерения пользователя и узнать все стороны вопроса, который его интересует.
Почему в подготовке папок мы указали 3 источника? Дело в следующем: в большинстве случаев сбор СЯ даже через Кей Коллектор происходит по сценарию - собрал фразы из левой колонки вордстата, почистил / обработал, пустил в работу. Этот вывод основан на анализе инструкций по сбору данных представленных в Рунете.
Некоторые используют бОльшее количество источников, однако все отталкиваются только от маркерных слов. Это абсолютно неправильно. Минусом такого подхода является то, что мы теряем большую часть ядра, если проводим сбор данных только по маркерным словам.
Представьте, что мы собрали фразы по ключевому слову “пластиковые окна”. Получили фразы по типу “купить пластиковые окна”, “пластиковые окна дешево” и другие популярные расширения ключевой фразы. Однако на этом ядро ни в коем случае не заканчивается, более того, основная его часть проявится только когда мы соберем данные по собранным фразам. То есть, если мы проведем сбор по фразам “купить пластиковые окна” и “пластиковые окна дешево”, мы увидим большое количество рабочих фраз, которые невозможно получить при сборе данных по маркерной фразе “пластиковые окна”. Одно это понимание уже может расширить наше семантическое ядро по отношению к конкурентам.
Именно исходя из этих соображений на этапе подготовки папок мы сделали 3 источника. Первый из них будет для сбора данных по подготовленным маркерным фразам. Во второй мы проведем сбор данных по фразам, которые получили на первом этапе. И в третий сбор данных по фразам второй итерации (лат. iteratio - повторяю).
Количество итераций выбрано исходя из практики. Как правило, самое большое количество фраз появляется в ходе второй итерации. Третья уже “выжимает соки” из наших фраз и является самой маленькой, но не менее ценной.
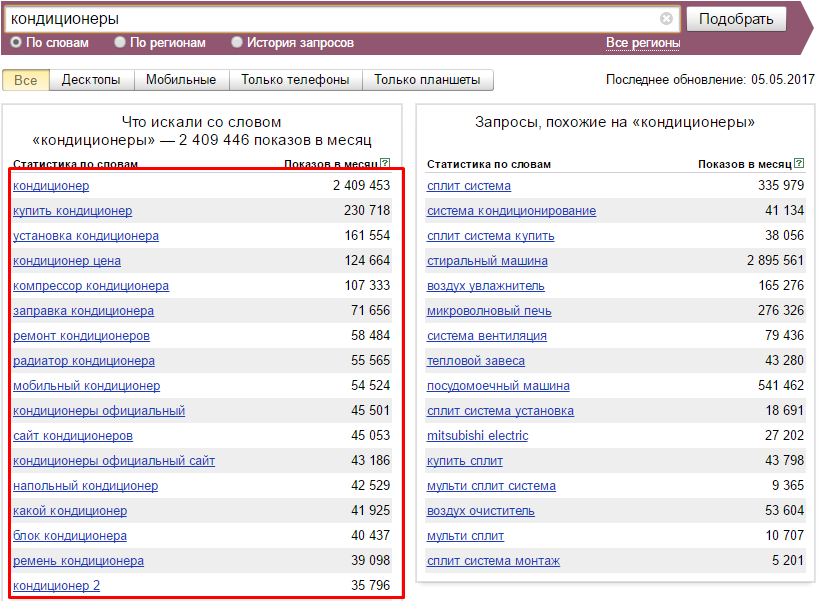
Теперь непосредственно к сбору данных. Рассмотрим настройку на примере фразы “кондиционеры”.
Первая итерация
Сбор
Рабочая область готова, выбираем ИСТОЧНИК 1 в правой части окна программы.

Нажимаем на первый источник “Пакетный сбор фраз из левой колонки Yandex.Wordstat”.

Настройки: “Добавить в текущую группу” (выделенная) и “Не добавлять фразу, если она уже есть в любой другой группе”. Вторая настройка требуется для избегания дублей, так как одна и та же фраза может прийти из разных источников. Чтобы не перебирать одинаковые фразы и ускорить процесс сбора данных выставляем эту настройку.
В программе есть функция “Распределить по группам”. Так мы можем сразу определить, в какую папку пойдут фразы по тому или иному маркерному запросу. С одной стороны, это очень удобно, так как упростит последующую группировку, с другой стороны, при работе с большими проектами нередки случаи, что в ходе итераций запросы одной тематики подмешиваются к запросам другой тематики. В этом время уйдет на сортировку запросов по нужным группам, если они попали не туда. Поэтому мы советуем загружать все данные в “Текущую папку”, а после проведения всех итераций производить группировку и распределение по группам. Инструменты КК помогут сделать это быстро и без лишних усилий.
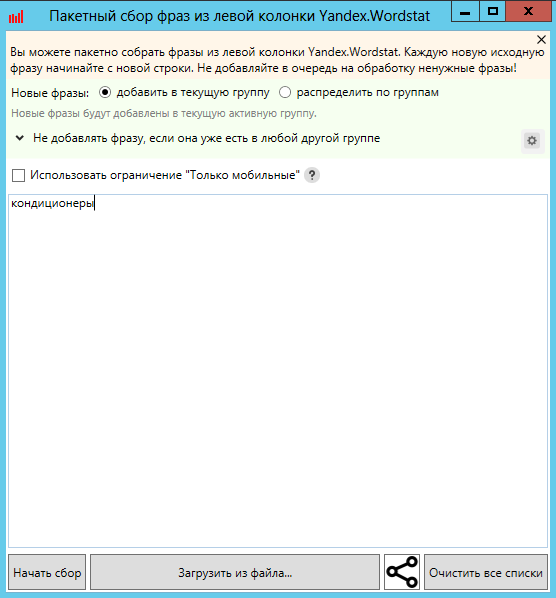
Запускаем "Начать сбор".
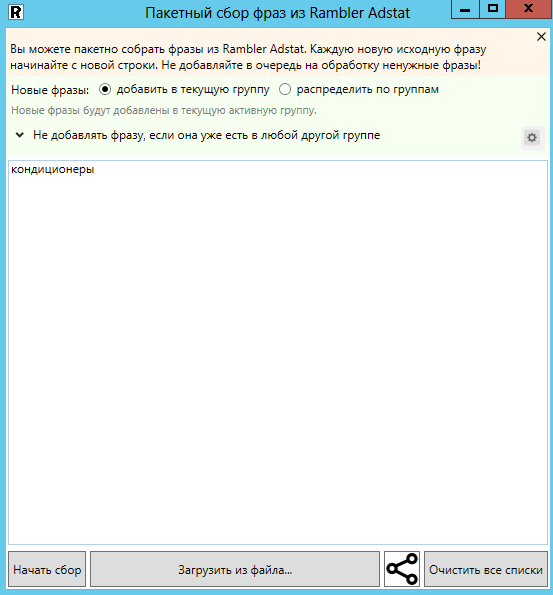
Пакетный сбор слов из Rambler.Adstat. Настройки идентичны настройкам в предыдущем источнике.
Пакетный сбор поисковых подсказок. Настраиваем сбор в текущую группу, “Не добавлять фразу если она есть в любой другой группе”.
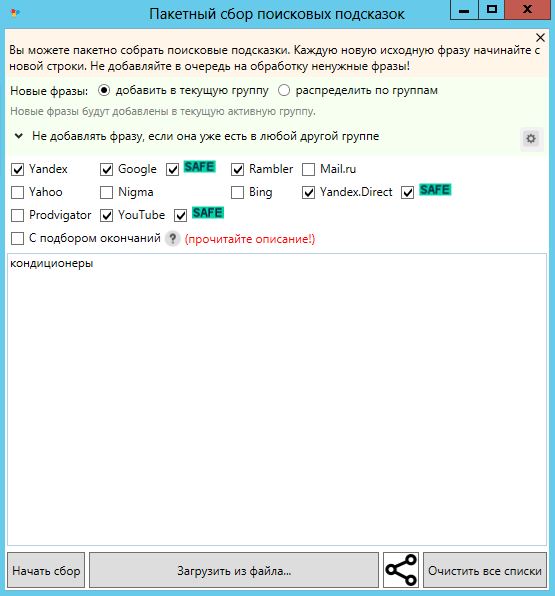
Сбор расширений ключевых фраз сервиса Roostat. Для данного источника требуется указать регион сбора, глубину сбора (ТОП) и для какой поисковой системы стоит собирать данные. Если нас интересуют информационные запросы без привязки к региону, то лучшим решением будет оставить регион “Москва”.

После окончания сбора по всем итерациям нам необходимо очистить группу от мусорных запросов.
Чистка
Эффективная чистка подробно рассмотрена в отдельной статье, так как заслуживает особого внимания. В данном примере можно отметить несколько быстрых способов:
Используем фильтрацию фраз.

Выбираем “содержит прочие символы”.
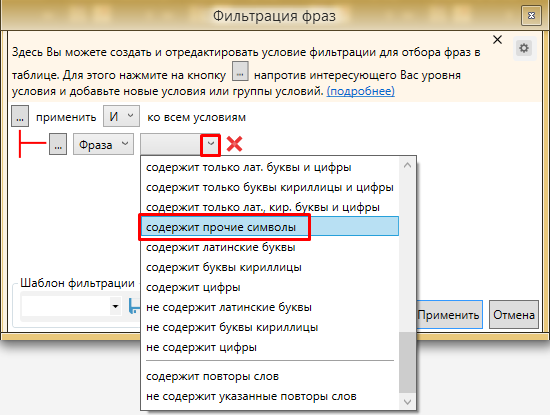
Жмем “Применить”. Кей Коллектор отфильтрует все фразы, которые содержат какие-либо спец символы или символы, которые не были указаны в настройках КК на замену или удаление. В 99% случаев это мусор, который не сыграет роли.
Выделяем все отфильтрованные фразы и переносим их в папку МУСОР.

Настройки переноса следующие
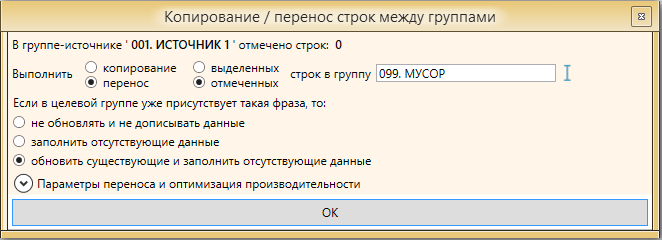
Есть возможность настроить параметры оптимизации, но по опыту работы с большими проектами это не столь необходимо и лучше оставим настройки стандартными.
Важно! Не удаляйте фразы, которые считаете мусорными! Переносите их в папку “МУСОР”. Так как предложенная методика предлагает несколько повторений сбора, в случае если мы удалим фразы они снова будут собраны. Если перенести их в папку “МУСОР”, сработает настройка “Не добавлять фразу, если она есть в любой другой группе” и мы сэкономим много времени, сил и финансов.
Вторым вариантом быстрой чистки является “содержит латинские символы”. Однако в этом случае все зависит исключительно от тематики. Если мы готовим ядро для интернет магазина, то данная настройка вычеркнет 30% ядра, а то и больше.
Следующий кропотливый, но эффективный способ. Переходим во вкладку “Данные”, жмем “Анализ групп”.

Этот инструмент полезен тем, что позволяет быстро выделить необходимые слова и все схожие с ним словоформы. Допустим, нам не нужны фразы “ремонт кондиционера”, которые мы получили в ходе сбора. Мы используем быстрый фильтр и вбиваем фразу “ремонт”

Выделяем все полученные результаты и сразу переносим их в МУСОР.
Третий способ - использование стоп-слов.
Если часто работать с СЯ, то постепенно наберется свой постоянный список стоп-слов, которые применяются в различных случаях. В любом случае можно легко найти готовые списки стоп-слов (или еще их называют минус слова) в интернете и добавить их в свой список, если они подходят по тематике. С помощью стоп-слов можно вычистить большое количество мусорных фраз сразу после сбора.
Сбор частот
После чистки собранных фраз от мусора можно запускать сбор частот для наших фраз. Выгодно изначально почистить фразы от мусора, а затем запускать сбор, так как это позволит сэкономить бюджет на антикапче и ускорить процесс сбора.
Сбор частот нужен нам для определения того, насколько часто пользователи вводят в поисковую систему тот или иной запрос и для определения их типа запроса. Соответственно, этим будет определяться приоритетность использования той или иной фразы.
Прежде чем запускать сбор необходимо разделить фразы на состоящие из 7 слов и фразы, состоящие из более чем 7 слов. Как описывалось ранее, это необходимо из-за того, что Директ не может обрабатывать запросы более 7 слов.
Используем фильтрацию по фразам.

Можно сохранить настройки фильтрации в шаблоны, чтобы иметь быстрый доступ к нужным настройкам.

Переносим полученные фразы в подготовленную папку 7+
Теперь всё готово для сбора частот. В папке ИСТОЧНИК 1 (не 7+), запускаем сбор данных из Яндекс.Директ.

Рекомендуемые настройки:
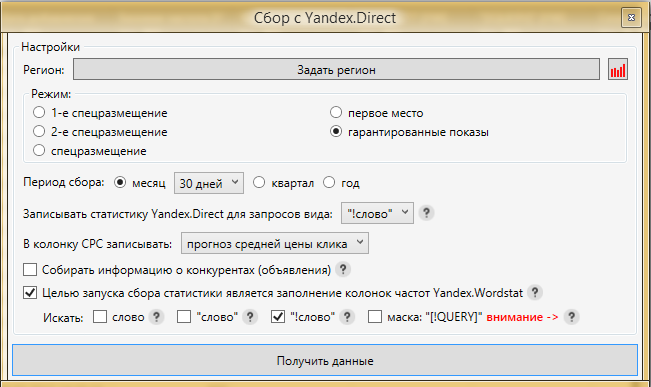
В последующем, после сбора всех итераций мы можем собрать информацию о конкурентах в Директе, если это необходимо для проекта.
Обратите внимание! В ходе обработки следите за сбором частот, так как на 1 аккаунт Яндекс.Директ приходится 100 капч, после чего необходимо перезапустить сбор. Также следите за общим количеством капч, если они достигли порога в 5 000 (выставленного в настройках) необходимо перезапустить Кей Коллектор.
В папке 7+, в которой находятся фразы из 8 слов и более запускаем сбор частот через Яндекс.Вордстат.
Яндекс.Директ обрабатывает частоты в разы быстрее “лупы” (Вордстата).
После того, как оба процесса закончатся переносим обратно фразы из папки 7+ в папку ИСТОЧНИК 1, так как теперь ничего не помешает работе с данными фразами в одной папке.
Для того, чтобы использовать только актуальные фразы с потенциальным трафиком необходимо провести чистку по частотностям. Порог, который можно оставить зависит от объема проекта. Если есть возможность и желание работать для каждого пользователя, то порог можно ставить и в 1 запрос в месяц. Однако в большинстве случаев порога частоты равным 5 более чем хватает. Для уточнения - речь идет не о СЯ для Директа, где в некоторых случаях используются и так называемые “пустышки”.
Для фильтрации по частоте используем инструмент фильтрация фраз, но в этот раз запускаем его в колонке “!” WS (или Частота “!” [YW], если вы не меняли стандартное название).
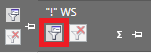

Выставляем порог “меньше 5” (или другое значение, в зависимости от предпочтений).
Отмечаем полученные фразы и переносим их в “МУСОР”.
Первая итерация очищена и готова к дальнейшей работе.
Вторая и третья итерации
Вторая итерация ничем не отличается от первой по последовательности действий. Но для сбора данных мы используем фразы, которые получили в ходе первой итерации. Для этого мы берем и выделяем все фразы в папке ИСТОЧНИК 1: выделили первую фразу, перешли в конец списка, с зажатым SHIFT’ом выделили последнюю фразу. Копируем: CTRL + C или правой кнопкой и “Копировать” (последний пункт выпадающего окна). После этого выделяем папку ИСТОЧНИК 2 и по очереди запускаем сбор из источников, как это проводилось в первой итерации.
Таким образом мы повторяем все пункты: Сбор, Чистка, Сбор частот, но используем фразы с первой итерации.
Третья итерация как понятно из логики - это сбор по фразам второй итерации.
Выделяем, копируем фразы, переходим на ИСТОЧНИК 3 и повторяем пункты: Сбор, Чистка, Сбор частот для фраз второй итерации.
В итоге, у нас должно получиться 3 папки с фразами, где следующая дополняет предыдущую. Практика показывает, что по объему от большего к меньшему чаще всего бывает так: ИСТОЧНИК 2, ИСТОЧНИК 1, ИСТОЧНИК 3. Если вдруг получилась друга ситуация, ничего страшного в этом нет, главное, чтобы все фразы соответствовали нашему ядру и тематике.
Работа с базами
На следующем этапе необходимо подключить базы. Как и описывали, мы используем базы Букварикс.
Интерфейс программы выглядит достаточно просто и не составит труда в нем разобраться. Берем нашу маркерную фразу “кондиционер” и добавляем её в левый столбец программы и жмем кнопку “Найти”.

Пример того, что показывает база изначально:

Цифра очень большая, 729 тысяч, но как видно из результатов кондиционер в данном случае рассматривается и как средство для волос, поэтому необходимо добавить в стоп слова такие запросы как: волос, орифлейм, питание, увлажнение и другие, которые не связаны с кондиционером как прибором. Постепенно выйдет адекватное количество фраз, а для баз это может быть порядка 80-120 тысяч.
Данные можно экспортировать в двух вариантах: текстовый файл и excel, это указывается в настройках.
После экспорта необходимо добавить полученные фразы в КК. Для этого необходимо нажать кнопку “Добавить фразы”

Можно добавить фразы обычным копированием, либо же загрузить их из файла

После добавления фраз необходимо провести для них такие пункты как: Чистка и Сбор частот.
При работе с базами часто бывает, что порядок действий выстраивается так: быстрая чистка по анализу групп, затем сбор частот и повторная чистка. Так как базы собираются за долгое время, при сборе частот большинство из запросов будет иметь месячную частоту 0 и их можно будет быстро отсеять фильтрацией по “!” WS, не тратя времени (но тратя деньги на антикапчу) вручную разбирая эти 80-120 или более фраз.
Этап сбора по базам дает как правило небольшой прирост в количестве фраз нашего СЯ, однако базы содержат большое количество запросов из 8 и более слов, которые редко встретишь в других источниках семантики.
Совмещение итераций
После того, как мы собрали все итерации, почистили их на мусор, собрали для них частоту и почистили фразы с частотой менее 5 необходимо совместить все полученные итерации и базы в одну группу. Это необходимо для последующей очистки на дубли, которые как правило разбросаны по итерациям.
Чтобы правильно сделать сборку необходимо копировать, не перемещать фразы из папки в папку. Копирование поможет нам восстановить прежний вариант, если вдруг мы случайно удалим фразы или сделаем что-то не так.
Для того, чтобы копировать фразы необходимо выполнить следующее:
Отмечаем все фразы в папке ИСТОЧНИК 1.
Жмем на “Перенос фраз в другую группу”, выбираем “СБОРКА”.
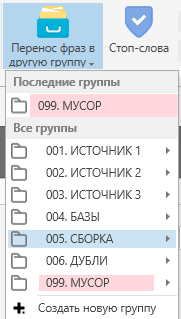
Переключаем опцию с “перенос”, на “копирование”
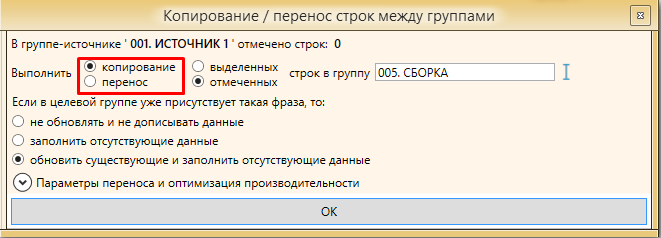
Жмем ОК.
Данную процедуру необходимо повторить для других итераций и баз, чтобы в папке “СБОРКА” мы получили все фразы нашего проекта (кроме мусорных).
Чистка на дубли
Чистка на дубли представляет собой очищение наших фраз от дубликатов, которые отличаются лишь перестановкой слов, например “купить кондиционер”, “кондиционер купить”. Частота у них будет показана одна и та же, однако в проекте будет использоваться только более правильная формулировка с точки зрения русского языка и восприятия человека. Кей Коллектор берет этот анализ на себя и делает это вполне качественно.
Для того, чтобы почистить фразы на дубли нам необходимо собрать частоту по маске “[!QUERY]” WS. Эта частота показывает маску фразы, а именно, то как пользователи вбивали данный запрос в зависимости от постановки слов. Допустим, после сбора этих частот фразы “гель для душа” и “для душа гель” будут иметь примерное соотношение 145 к 5, то есть первая фраза употребляется гораздо чаще второй. Нередко бывает, что частота QUERY по значению больше, чем “!” WS, однако это обуславливается тем, что она включает в себя сумму частот “!” WS разных формулировок фразы. Например, если фраза одинаково часто используется в обоих вариантах, а их точная частота (“!”) выглядит как 150 и 10, то их частота QUERY будет выглядеть как 80 и 80. Этот пример редко можно встретить, но он “на пальцах” и четко описывает отображаемые в программе данные.
Как же программа чистит подобные дубли? Система собирает данные по маске QUERY и делает “умную отметку”, а именно выделяет и предлагает оставить фразы с наиболее высоким показателем QUERY.
Для того, чтобы собрать частоту QUERY необходимо сделать следующее:
Выделяем папку СБОРКА.
На панели инструментов выбираем “лупу” и функцию “Собрать частоты по маске “[!QUERY]””.

После окончания сбора проведем саму чистку дублей.
Переходим во вкладку Данные и включаем инструмент “Анализ неявных дублей”

После подсчета перед нами откроется окно с предложенными неявными дублями.
Проводим следующую настройку
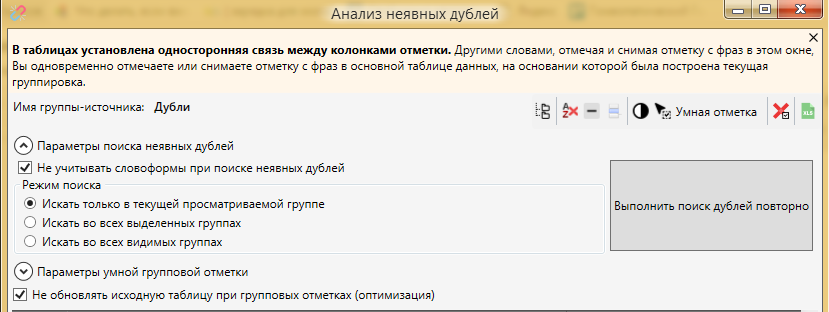
Такая настройка, как “Не учитывать словоформы при поиске неявных дублей” отвечает за то, что дублями будут признаваться формулировки с разными окончаниями и словоформами. Например, при включенной опции программа посчитает фразы “купить кондиционер” и “купить кондиционеры” дублями. В целом, эта опция оправдывает себя, так как в большинстве случаев, склонения которые предлагаются как дубли таковыми и являются, поскольку поисковые системы самостоятельно меняют словоформы запроса и сопоставляют с заголовками страниц. Поэтому, после ряда тестов мы посчитали, что эта функция полезна и стоит ее включать.
После того, как система обработала дубли в нашем проекте необходимо выполнить “умную отметку”.

Кей Коллектор отметит в таблице все фразы, которые он считает дублями. В зависимости от объема рекомендуется проверить взглядом предложенную отметку. Если вдруг нам кажется, что какая-то фраза звучит неестественно, но показатель QUERY выше, чем у более “правильной” фразы, то стоит посмотреть источник фразы, так как в большинстве случаев такие варианты возникают при подсказках поисковых систем. То есть пользователь вбил “шины”, Яндкс предложил ему “купить” и он выбрал, соответственно будет подсчитано, что эта формулировка используется часто. Такие фразы стоит оставлять, так как они не меняют семантического смысла, а переставить слова в заголовке в будущем не составить труда.
Отмеченные фразы переносим (не забудьте поменять настройки с копирования) в папку дубли.
Нередко бывает так, что при сборе попадаются фразы с повторением слов, допустим “как приготовить кашу как”. При этом у них есть точная частота и они не определяются как дубли системой КК. Для этого есть следующее решение, настраиваем фильрацию фраз следующим образом:
Фраза содержит повторы слов
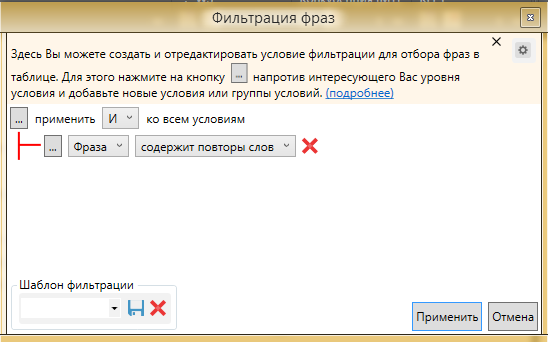
Добавляем второе условие - QUERY равно 0. Для того, чтобы добавить условие жмем на “…” на верхнем уровне.
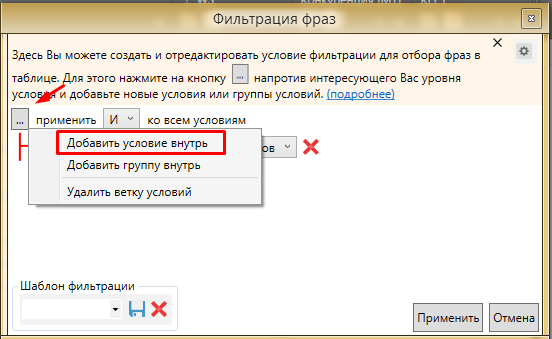
И добавляем второе условие

Нажимаем применить. При данном фильтре мы задаем условие: во фразе содержатся повторы слов и частота написания пользователями фразы в таком варианте равняется 0. Таким образом мы исключаем фильтрацию слов с повторением предлогов, которые могут попасться если мы просто оставим фильтр “содержит повторы слов”. Для более тщательной чистки, QUERY можно поставить не равным 0, а меньше 5 или меньше 10. Чтобы не получилось так, что мы выделим фразу с точной частотой 5 и QUERY 4, можно добавить третье условие, что “!” WS более 10. С помощью этих фильтров можно максимально очистить семантическое ядро от подобного мусора.
Полученные фразы переносим в подпапку дублей “ПОВТОРЫ”.
На этом этапе можно сказать, что наше ядро готово к работе и группировке.
Итоги
Предложенный вариант сбора семантического ядра в Кей Коллекторе подходит для проектов любого масштаба. Разве что для мелких проектов возможно не использовать базы, если количество фраз оттуда будет слишком большим.
Мы рассмотрели сбор максимально полного семантического ядра. Этот способ заключается в нескольких итерациях, которые собирают все варианты и тематики связанные с нашими маркерными словами. В данной методике не использовалась привязка к региону, что часто требуется для локальных коммерческих проектов и практически не рассматривались особенности сбора СЯ для контекстной рекламы.
Если обобщить преимущества и недостатки такой методики, то выйдет примерно следующее:
Плюсы методики:
Максимально полное ядро. Мы на голову обойдем конкурентов, которые не используют несколько итераций в сборе СЯ.
Эффективная чистка на дубли и повторы слов.
Эффективная чистка на мусор (основные моменты), которая также является частью этой методики.
Использование баз, как дополнительного источника семантики.
Минусы методики:
Возможно, продолжительный по времени анализ и ход всех итераций. Однако результат того стоит.
Сложность в первоначальном следовании “инструкции” и понимании всех методик.
Необходимость бОльшего бюджета на антикапчу, так как объем фраз для обработки больше, чем в сборе данных с одной итерацией.
